
24.1. What's New in Apache 2.0
Whereas Apache 1.2 and 1.3 were based on the NCSA httpd code base, Apache 2.0 rewrote big chunks of the 1.3 code base, mainly to support numerous new features and enhancements. Here are the most important new features:
- Apache Portable Runtime (APR)
-
The APR presents a standard API for writing portable
client and server applications, covering file I/O, logging, shared
memory, threads, managing child processes, and many other
functionalities needed for developing the Apache core and third-party
modules in a portable and efficient way. One important effect is that
it significantly simplifies the code that uses the APR, making it
much easier to review and understand the Apache code, and increasing
the number of revealed bugs and contributed patches.
The APR uses the concept of memory pools, which significantly simplifies the memory-management code and reduces the possibility of memory leaks (which always haunt C programmers).
- I/O filtering
-
Apache 2.0 allows multiple
modules to filter both the request and the
response. Now one module can pipe its output to another module as if
it were being sent directly from the TCP stream. The same mechanism
works with the generated response.
With I/O filtering in place, simple filters (e.g., data compression and decompression) can easily be implemented, and complex filters (e.g., SSL) can now be implemented without needing to modify the the server code (unlike with Apache 1.3).
To make the filtering mechanism efficient and avoid unnecessary copying, the bucket brigades model was used, as follows.
A bucket represents a chunk of data. Buckets linked together comprise a brigade. Each bucket in a brigade can be modified, removed, and replaced with another bucket. The goal is to minimize the data copying where possible. Buckets come in different types: files, data blocks, end-of-stream indicators, pools, etc. You don't need to know anything about the internal representation of a bucket in order to manipulate it.
The stream of data is represented by bucket brigades. When a filter is called, it gets passed the brigade that was the output of the previous filter. This brigade is then manipulated by the filter (e.g., by modifying some buckets) and passed to the next filter in the stack.
Figure 24-1 depicts an imaginary bucket brigade. The figure shows that after the presented bucket brigade has passed through several filters, some buckets were removed, some were modified, and some were added. Of course, the handler that gets the brigade doesn't know the history of the brigade; it can only see the existing buckets in the brigade. We will see bucket brigades in use when discussing protocol handlers and filters.
- Multi-Processing Model modules (MPMs)
-
In the previous Apache generation, the
same code base was trying to manage incoming requests for different
platforms, which led to scalability problems on certain (mostly
non-Unix) platforms. This also led to an undesired complexity of the
code.
Apache 2.0 introduces the concept of MPMs, whose main responsibility is to map the incoming requests to either threads, processes, or a threads/processes hybrid. Now it's possible to write different processing modules specific to various platforms. For example, Apache 2.0 on Windows is much more efficient and maintainable now, since it uses mpm_winnt, which deploys native Windows features.
Here is a partial list of the major MPMs available as of this writing:
- prefork
- The prefork MPM implements Apache 1.3's preforking model, in which each request is handled by a different forked child process.
- worker
- The worker MPM implements a hybrid multi-process/multi-threaded approach based on the pthreadsstandard.
- mpmt_os2, netware, winnt, and beos
- These MPMs also implement the hybrid multi-process/multi-threaded model, like worker, but unlike worker, each is based on the native OS thread implementations, while worker uses the pthread library available on Unix.
On platforms that support more than one MPM, it's possible to switch the used MPMs as the need changes. For example, on Unix it's possible to start with a preforked module, then migrate to a more efficient threaded MPM as demand grows and the code matures (assuming that the code base is capable of running in the threaded environment).
- New hook scheme
- In Apache 2.0 it's possible to dynamically register functions for each Apache hook, with more than one function registered per hook. Moreover, when adding new functions, you can specify where the new function should be added—for example, a function can be inserted between two already registered functions, or in front of them.
- Protocol modules
- The previous Apache generation could speak only the HTTP protocol. Apache 2.0 has introduced a "server framework" architecture, making it possible to plug in handlers for protocols other than HTTP. The protocol module design also abstracts the transport layer, so protocols such as SSL can be hooked into the server without requiring modifications to the Apache source code. This allows Apache to be extended much further than in the past, making it possible to add support for protocols such as FTP, NNTP, POP3, RPC flavors, and the like. The main advantage is that protocol plug-ins can take advantage of Apache's portability, process/thread management, configuration mechanism, and plug-in API.
- GNU Autoconf-based configuration
- Apache 2.0 uses the ubiquitous GNU Autoconf for its configuration process, to make the configuration process more portable.
- Parsed configuration tree
-
Apache 2.0 makes the parsed configuration tree available at runtime,
so modules needing to read the configuration data (e.g., mod_info)
don't have to re-parse the configuration file, but
can reuse the parsed tree.
All these new features boost Apache's performance, scalability, and flexibility. The APR helps the overall performance by doing lots of platform-specific optimizations in the APR internals and giving the developer the already greatly optimized API.
The I/O layering helps performance too, since now modules don't need to waste memory and CPU cycles to manually store the data in shared memory or pnotes in order to pass the data to another module (e.g., to provide gzip compression for outgoing data).
And, of course, an important impact of these features is the simplification and added flexibility for the core and third-party Apache module developers.
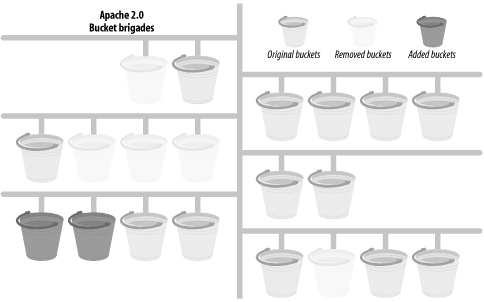
Figure 24-1. Imaginary bucket brigade
Continue to:

